Recently, I had a long discussion on “what library to use to solve mathematical problems with Python in production use”. Well, most introductions into Python and “best practices” have a strong focus on NumPy (especially for vectorization). However, for small lists and matrices for-loops CPython’s math library is still faster than the best practice of using NumPy. Moreover, neither CPython.math nor NumPy use parallel computing for basic operations. NumPy only uses parallel processing for certain functions but not for the very basic functions. Considering that we have two very prominent deep learning frameworks with built-in parallelism, namely PyTorch and TensorFlow, which can be utilized as a general purpose math library as well, we have to ask ourselves if we can use them as a drop-in replacement for CPython.math or NumPy and if so starting at what list/matrix/array/tensor size. Furthermore, they come with easy to use GPGPU (CUDA) support which enables use to use a GPU. The big question is: when to deploy which library.
NB!: This is still a kind of a micro-benchmark and does not resemble speed-improvements of a whole project!.
Setup
The source code is available on GitHub.
We are going to speed-test the following functions
functions = {}
functions["sin"] = math.sin
functions["cos"] = math.cos
functions["tan"] = math.tan
functions["asin"] = math.asin
functions["acos"] = math.acos
functions["atan"] = math.atan
functions["exp"] = math.exp
functions["sinh"] = math.sinh
functions["cosh"] = math.cosh
functions["tanh"] = math.tanh
functions["abs"] = abs
functions["ceil"] = math.ceil
functions["floor"] = math.floor
functions["sqrt"] = math.sqrt
on lists containing 1 to 1000000 elements of random numbers and on matrices containing 1x1 to 10000x10000 random numbers.
We are going to compare:
- CPython.math (written in C!)
- NumPy
- PyTorch (CPU)
- PyTorch (GPU)
- TensorFlow (CPU)^
^I’m no longer using TF in production and for some reason by GPU was not detected by default and I’m not going to waste time setting it up
It is important to remember that we have to use loops with CPython. We’re using standard CPython for-loops and not for-loops optimized with Cython. This way it stays a half-way fair comparison between CPython.math and NumPy. Since it is interesting to understand “default behavior”, we should not parallelize loops and functions for CPython.math and NumPy.
Each function and dataset combination is measured for 200 iterations so we get some useful information.
Benchmarks were performed on an Intel Xeon E5-1620 (v1) and a NVIDIA GTX 1060 6GB.
Results
Averaged across all functions
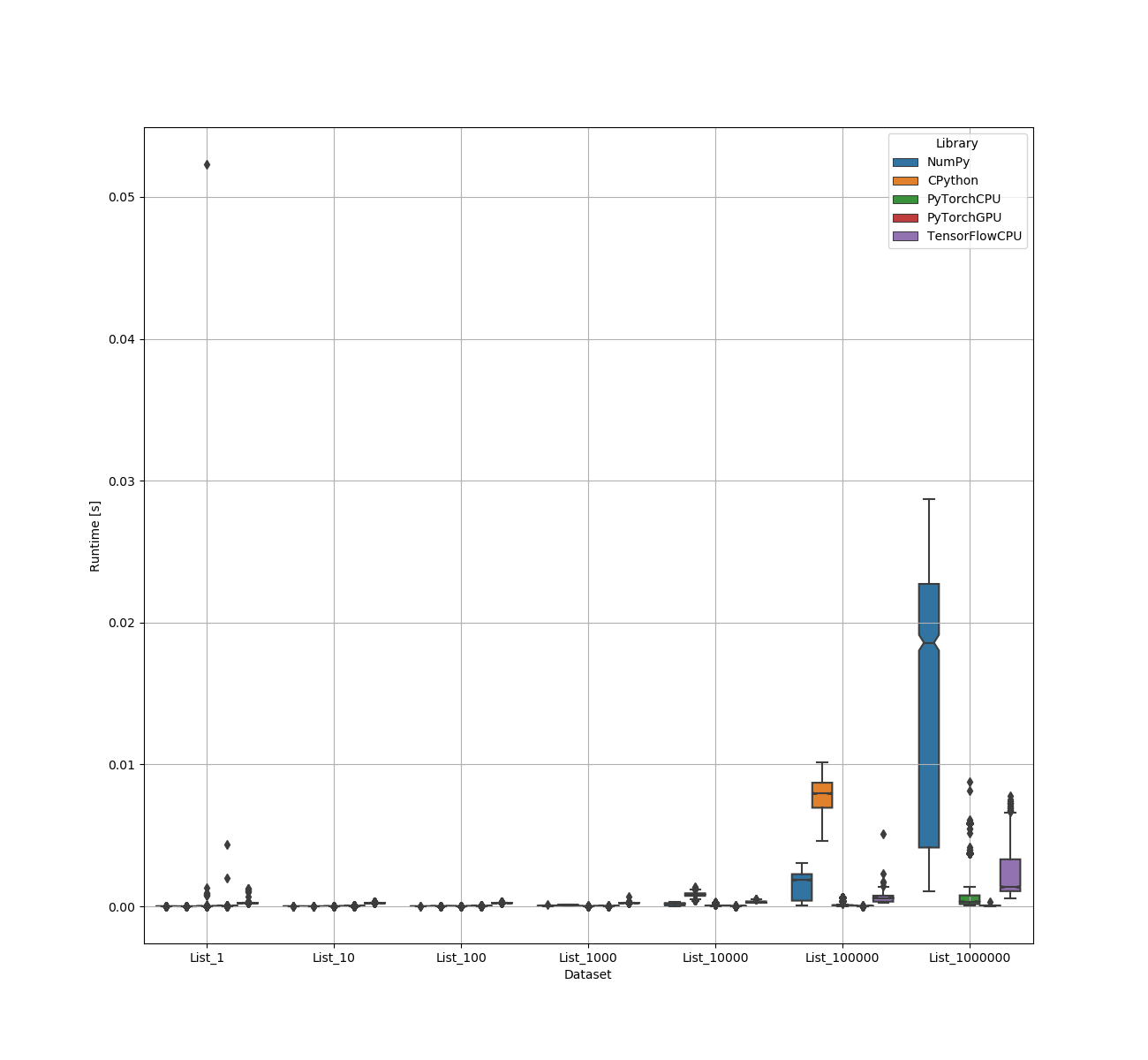

When it comes to lists, it seems like for lists up to a size of 10 elements, CPython.math has a little advantage over NumPy whereas NumPy loses it’s advantage over PyTorch between lists of 100 and 1000 items.
TensorFlow (CPU) struggles with a lot of overhead until a list of 100000. Then it reaches wins the competition with NumPy.
PyTorch is the fastest starting with lists of 1000 elements. Between 10000 and 100000 elements, the GPU version is starting to provide us with a faster solution.


When we look at working with a matrix, it is clear that CPython.math loses a lot of time due to the inefficient double for-loops. NumPy wins for small matrices such as 10x10 matrices but loses against PyTorch using larger matrices.
At matrices of size 1000x1000, PyTorch GPU outperforms PyTorch using a CPU. With smaller matrices we are experiencing a lot of CUDA overhead.
It takes a 10000x10000 matrix for TensorFlow to catch up with PyTorch (both CPU).
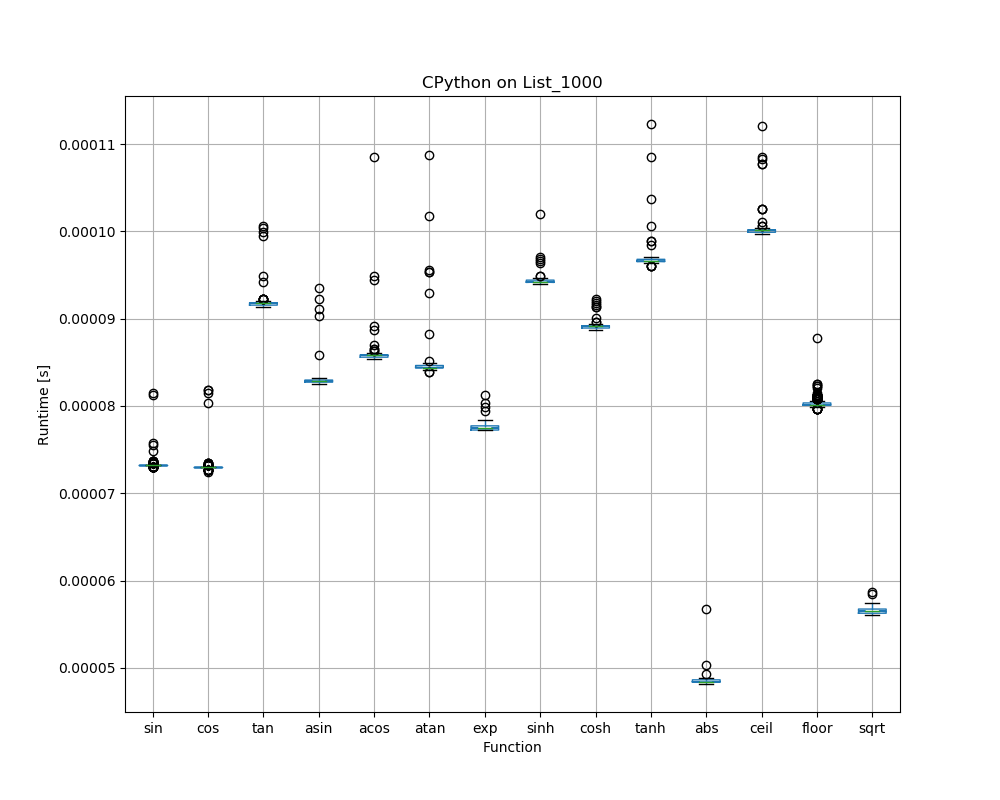
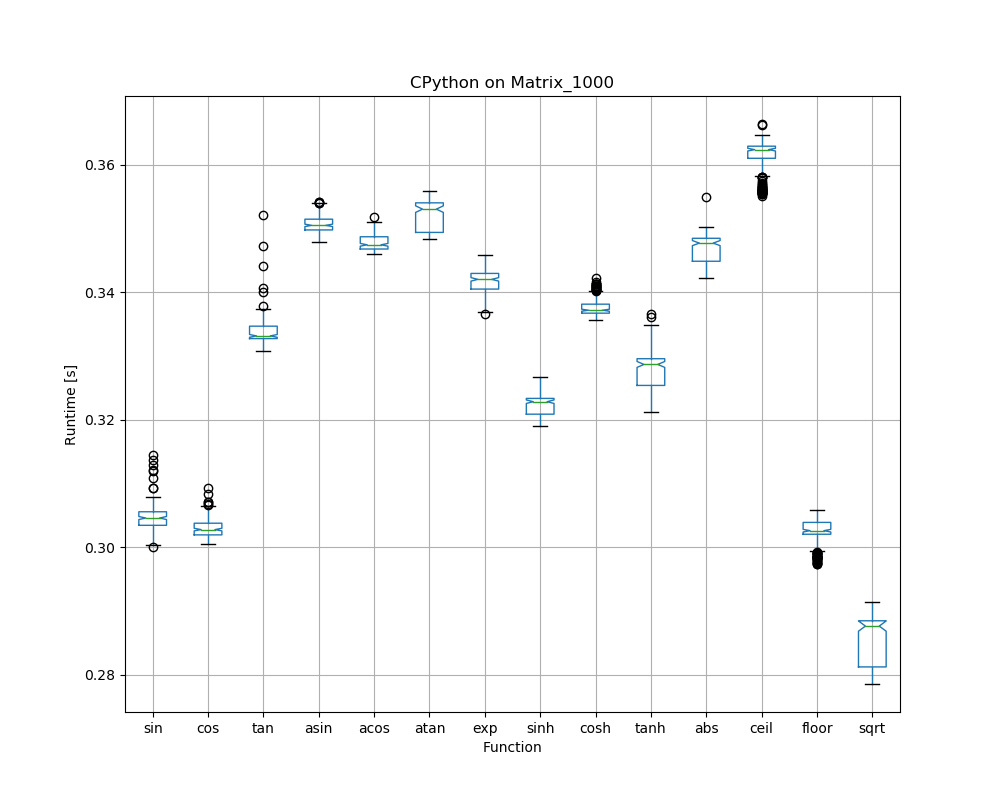
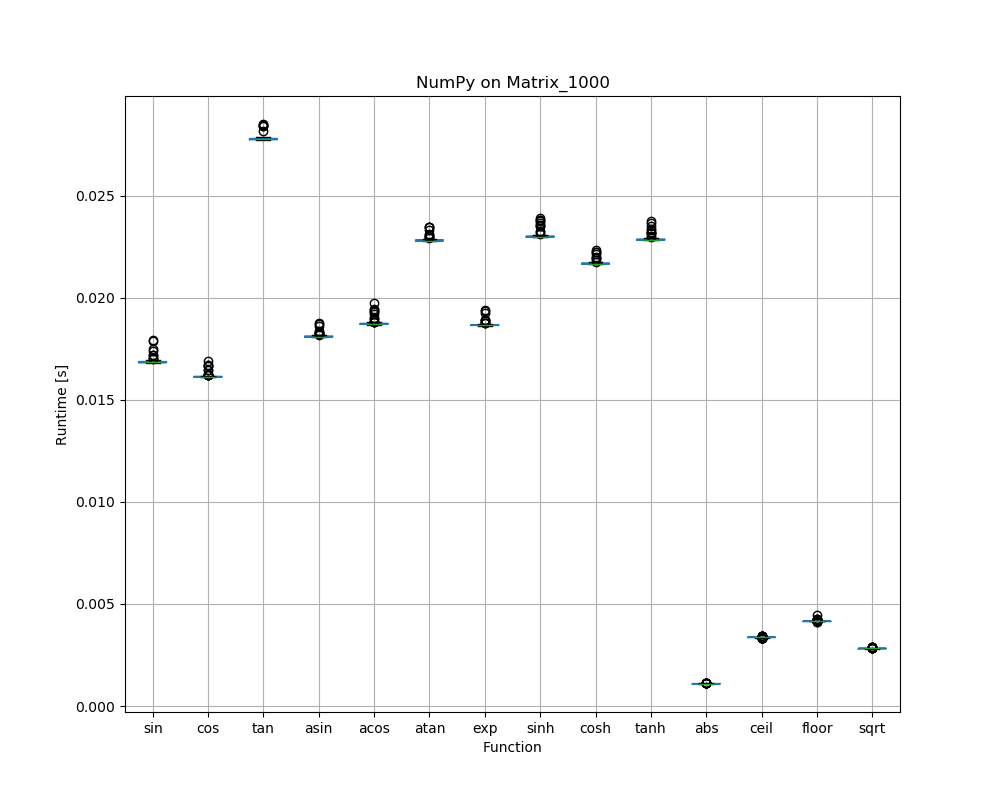
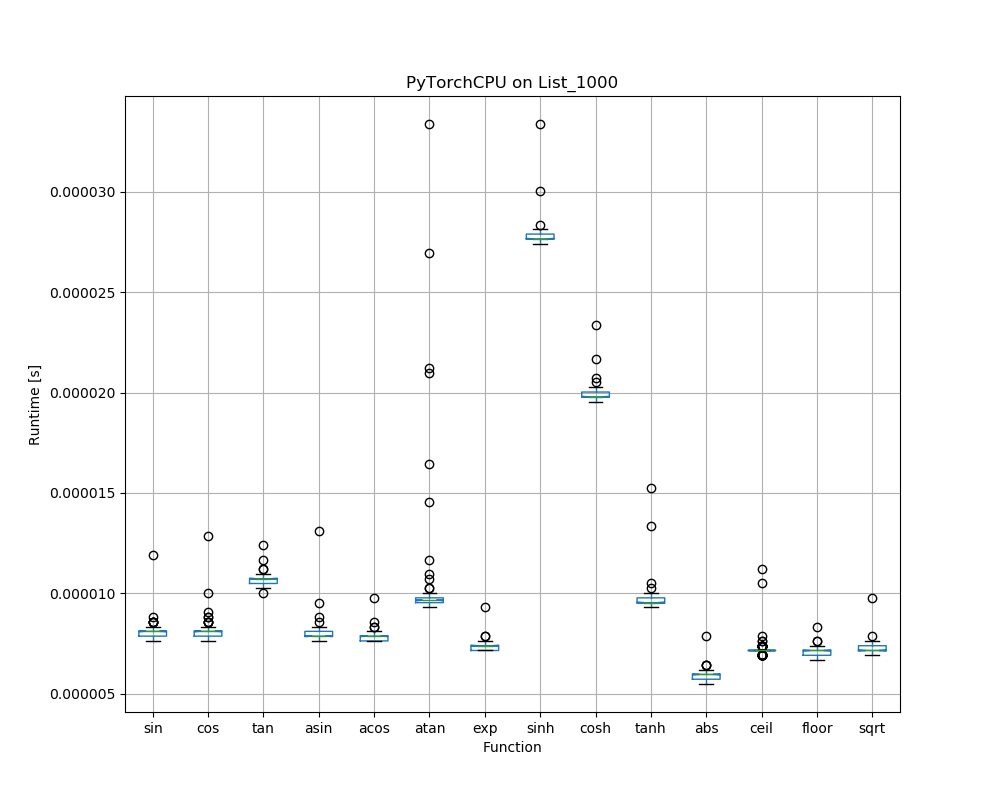
Speed differences of functions within a library
So far we looked at average results across all 14 functions per library. The large error bars (whiskers) are due to the fact that there are quite significant speed differences between functions within a library: