Deep learning is an interesting field. A couple of years ago, it was all about benchmark performance (e.g. mAP), nowadays it is more about inference speed. However, these comparisons are usually not documented correctly. Very important things are missing, such as batch sizes. But let’s have a look at a concrete example.
Recently, I read a paper by Cai et al. (2020) called “Once for All: Train One Network and Specialize it for Efficient Deployment”. The github repo contains this image:
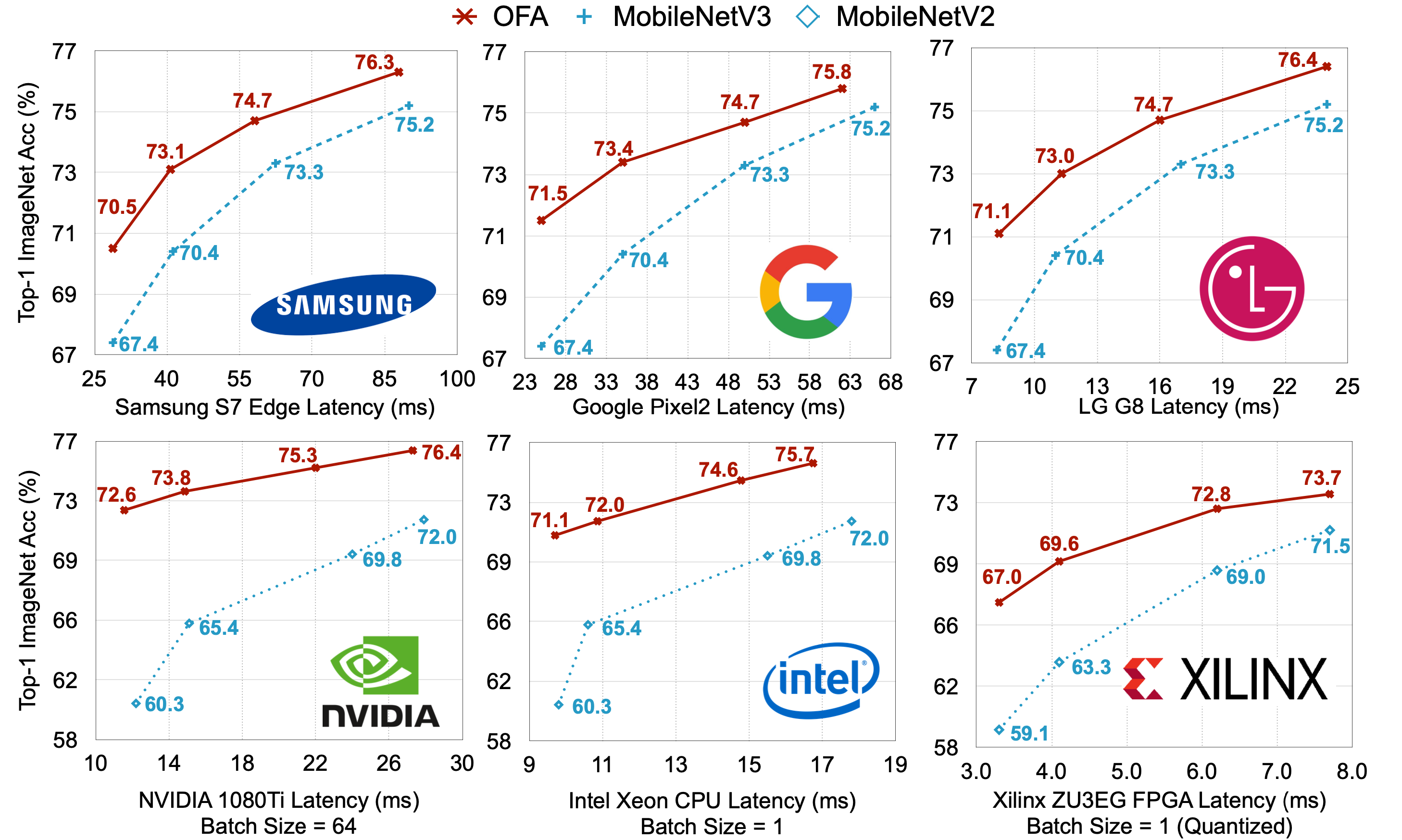
First, I would like to point out that I’m happy that they put the batch sizes even in the figure and not only in the text. However, what is the problem with this figure? Well, hardly anyone will read it carefully, and therefore compare performances “directly”. Further, there remains the question if this is the pure run time or if all memory I/O is added to it as well.